[혼공학습단 10기] 4주차 미션 : Chapter 05

4주차 미션은 무엇일까요?
[기본 미션]
교차 검증을 그림으로 설명하기
[선택 미션]
Ch.05(05-3) 앙상블 모델 손코딩 코랩 화면 인증하기
[기본 미션]
교차 검증을 그림으로 설명하기
교차 검증은 훈련 세트를 여러 폴드로 나눈 다음 한 폴드가 검증 세트의 역할을 하고 나머지 폴드에서는 모델을 훈련하고, 모든 폴드에 대해 검증 점수를 얻어 평균하는 방법이다.
아래의 그림은 3-폴드 교차 검증의 예시이다.
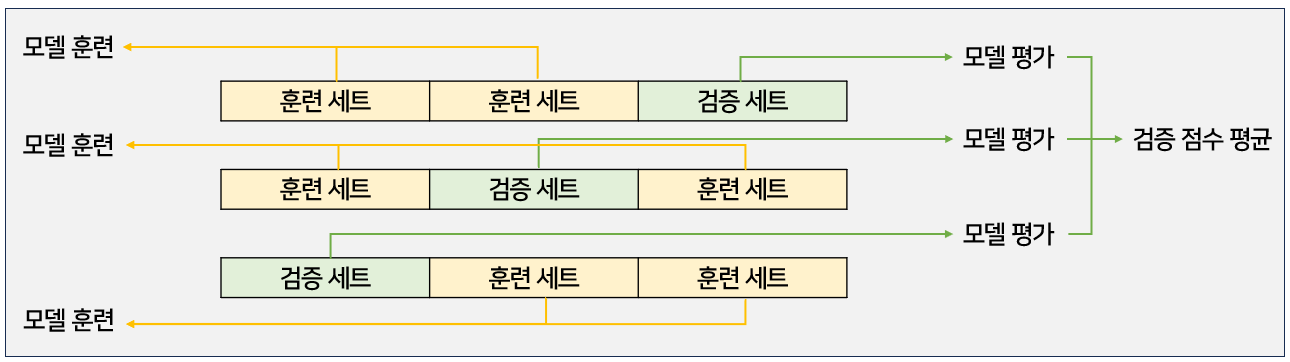
cross_validate()는 교차 검증을 수행하는 함수이다.
- 첫 번째 매개변수: 모델 객체
- 두 번째 매개변수: 특성 데이터
- 세 번째 매개변수: 타깃 데이터
- scoring 매개변수: 검증에 사용할 평가 지표 지정 - 예) accuracy(분류: 정확도), r2(회귀: 결정계수) 등
- cv 매개변수: 교차 검증 폴드 수나 스플리터 객체 지정(기본값: 5) - KFold 클래스(회귀), StratifiedKFold 클래스(분류) 등
[선택 미션]
Ch.05(05-3) 앙상블 모델 손코딩 코랩 화면 인증하기
앙상블 학습은 여러 개의 모델을 훈련하는 머신러닝 알고리즘으로 랜덤 포레스트, 엑스트라 트리, 그레디언트 부스팅, 히스토그램 기반 그래디언트 부스팅이 있다.
<화이트 와인 분류 문제-앙상블 모델 코딩>
와인 데이터셋(wine_csv_data)를 불러오고 훈련 세트와 테스트 세트로 나눈다.

랜덤 포레스트: 대표적인 결정 트리 기반의 앙상블 기법으로 부트스트랩 샘플을 사용한다. 부트스트랩 샘플을 사용하여 랜덤하게 일부 특성을 선택하여 트리를 만든다.
RamdomForestClassifier 클래스
- n_estimators 매개변수: 앙상블을 구성할 트리의 개수를 지정(기본값: 100)
- criterion 매개변수: 불순도 지정(기본값: 'gini')
- max_depth 매개변수: 트리가 성장할 최대 깊이 지정(기본값: None)
- min_samples_split 매개변수: 노드를 나누기 위한 최소 샘플 개수(기본값: 2)
- max_features 매개변수: 최적의 분할을 위해 탐색할 특성의 개수 지정(기본값: auto)
- bootstrap 매개변수: 부트스트랩 샘플 사용 여부 지정(기본값: True)
- oob_score 매개변수: OOB 샘플을 사용하여 훈련한 모델을 평가할지 지정(기본값: False)
- n_jobs 매개변수: 병렬 실행에 사용할 CPU 코어 수 지정(기본값: 1)

엑스트라 트리: 랜덤 포레스트와 비슷하게 결정트리를 사용하여 앙상블 모델을 만들지만 부트스트랩 샘플을 사용하지 않는다. 결정트리의 노드를 랜덤하게 분할하여 과대적합을 감소시킨다.
ExtraTreesClassifier 클래스
- n_estimators, criterion, max_depth, min_samples_split, max_features 매개변수: 랜덤 포레스트와 동일
- bootstrap 매개변수: 부트스트랩 샘플 사용 여부 지정(기본값: False)

그레디언트 부스팅: 이전 트리의 손실을 보완하는 방식으로 얕은 결정 트리를 연속적으로 추가하여 손실 함수를 최소화하는 앙상블 방법이다.
GradientBoostingClassifier 클래스
- loss 매개변수: 손실함수 지정(기본값: 로지스틱 손실함수인 'deviance')
- learning_rate 매개변수: 트리가 앙상블에 기여하는 정도 조절(기본값: 0.1)
- n_estimators 매개변수: 부스팅 단계를 수행하는 트리의 개수(기본값: 100)
- subsample 매개변수: 사용할 훈련 세트의 샘플 비율 지정(기본값: 1.0)
- max_depth 매개변수: 개별 회귀 트리의 최대 깊이(기본값: 3)

히스토그램 기반 그레디언트 부스팅: 훈련 데이터를 256개의 정수 구간으로 나눠 빠르고 높은 성능을 낸다.(그래디언트 부스팅의 속도를 개선함)
HistGradientBoostingClassifier 클래스
- learning_rate 매개변수: 학습률 또는 감쇠율(기본값: 0.1)
- max_iter 매개변수: 부스팅 단계를 수행하는 트리의 개수(기본값: 100)
- max_bins 매개변수: 입력 데이터를 나눌 구간의 개수(기본값: 255)

XGBoost와 LightGBM

출처: 한빛미디어, 혼자 공부하는 머신러닝+딥러닝