
2달동안 머신러닝과 딥러닝을 열심히 공부하기 위해 혼공학습단 10기를 신청했고, 혼공학습단 10기로 선정이 되었습니다.
좋은 소식은 SQLD 자격증 시험을 미루다가 6월 10일에 시험을 보고, SQLD 자격증을 최근에 합격했습니다.
혼공학습단 7기로 혼자 공부하는 SQL로 MySQL에 대한 기초 개념과 학습하고, 코드 실습을 했던 것이 자격증 시험 공부를 할 때 많은 도움이 되었습니다! 물론 자격증 시험 전에 2주동안 기출문제를 열심히 풀었습니다~!

1주차 미션은 무엇일까요~?
[기본 미션]
코랩 실습 화면 캡처하기
[선택 미션]
Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
[기본 미션]
코랩 실습 화면 캡처하기
코랩을 활용하여 "Chapter 01-3. 마켓과 머신러닝" 실습 화면을 캡처했습니다!
1. 생선을 분류하기 위해서 35마리의 도미 데이터(bream_length, bream_weight)와 14마리의 빙어 데이터(smelt_length, smelt_weight)를 준비했고, 생선의 길이(cm)와 생선의 무게(g)를 나타내고 있습니다.

2. 시각화 대표 패키지인 matplotlib을 임포트하고, scatter()함수를 사용하여 산점도를 그렸습니다. 산점도는 x, y축으로 이루어진 좌표에 두 변수의 관계를 표현할 수 있는 방법으로 x축을 길이, y축을 무게로 아래의 산점도를 그렸습니다.
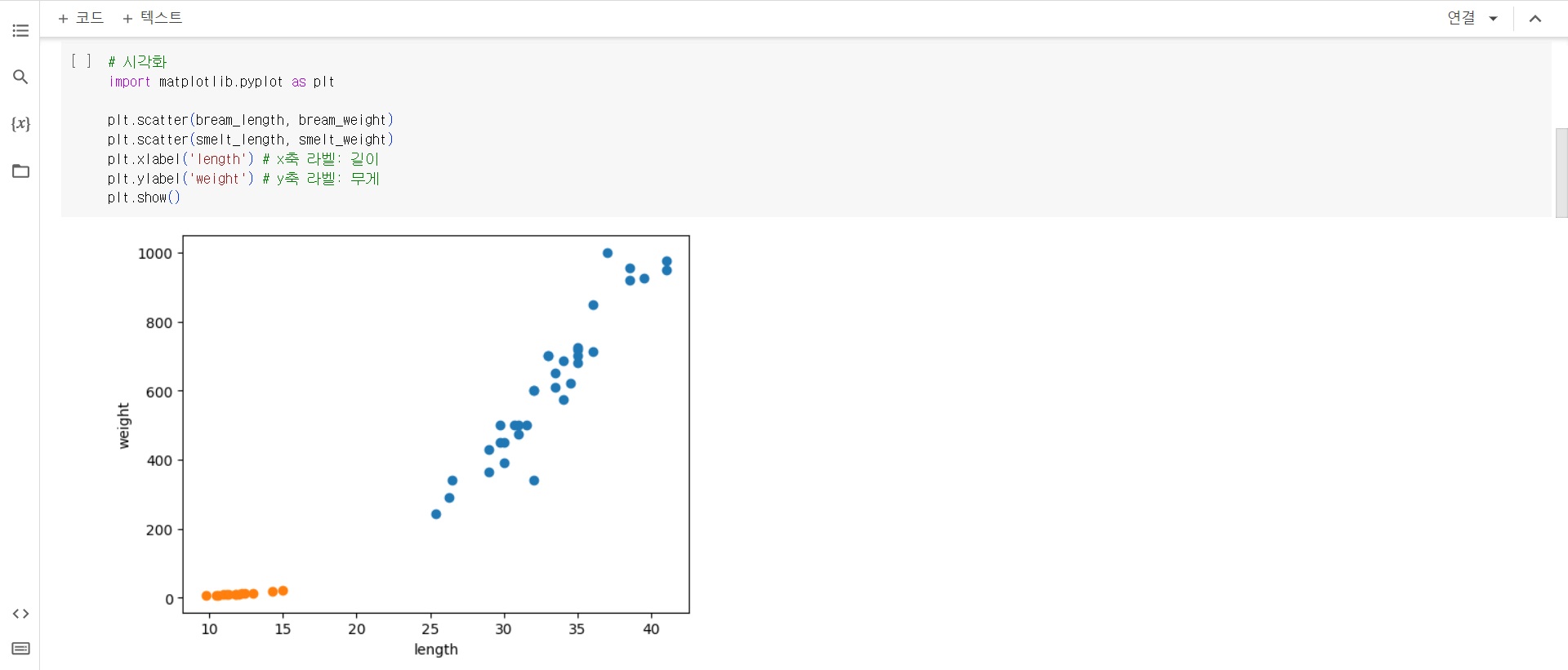
3. k-최근접 이웃 알고리즘을 활용하여 도미와 빙어의 데이터를 구분하기 위해 length 리스트(도미의 길이와 빙어의 길이를 합친 리스트)와 weight(도미의 무게와 빙어의 무게를 합친 리스트)를 만들었습니다. 그리고 zip()함수를 활용하여 2차원 리스트를 만들었습니다. 2차원 리스트는 [[length1, weight1], [length2, weight2], ..., [length49, weight49]]로 구성됩니다. 도미는 1(찾으려는 대상), 빙어는 0(그 외)으로 하여 fish_target 리스트를 만들었습니다.

4. KNeighborsClassifier 클래스의 객체를 만들고 k-최근접 이웃 알고리즘을 구현합니다. fit() 메서드로 주어진 데이터로 알고리즘을 학습하고, score() 메서드로 모델을 평가합니다.

5. 새로운 데이터 [30, 600]은 도미와 빙어 중 어디에 속하는지 predict() 메서드로 확인하면 [1]로 도미라고 판단을 하게 됩니다.
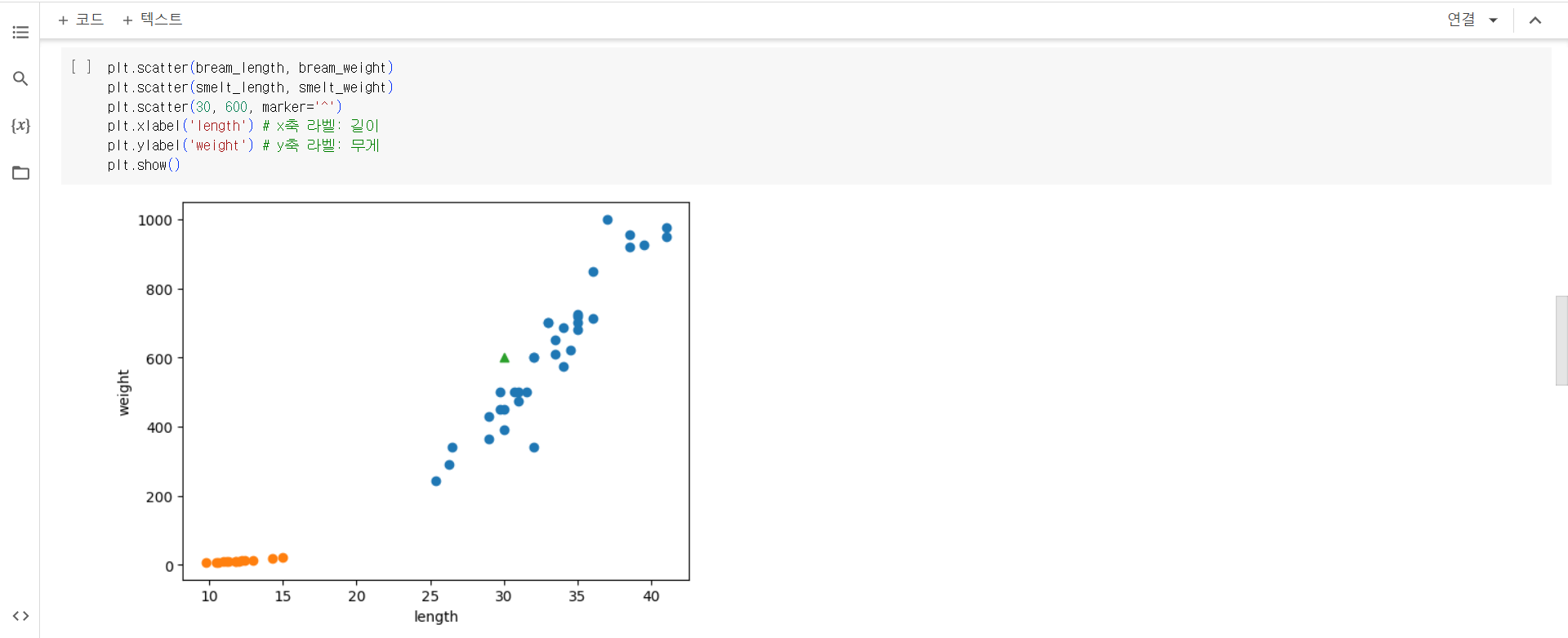


6. n_neighbors 매개변수를 기본값 5에서 49로 바꾸면 어떻게 될까요? 49개의 fish_data 데이터를 무조건 도미로 예측하게 학습이 되어 정확도가 35/49가 됩니다. 따라서 해당 데이터에서 n_neighbors를 기본값인 5로 두는 것이 좋습니다.

[선택 미션]
Ch.02(02-1) 확인 문제 풀고, 풀이 과정 정리하기
✅문제 1. ① 지도학습
머신러닝 알고리즘은 지도학습과 비지도학습으로 나눌 수 있고, 입력과 정답(타깃)이 있을 때 지도학습 알고리즘을 사용하고, 입력 데이터만 있을 때는 비지도학습 알고리즘을 사용합니다!
✅문제 2. ④ 샘플링 편향
머신러닝의 정확한 평가를 위해 데이터는 훈련 세트와 테스트 세트가 필요합니다. 이때, 훈련 세트와 테스트 세트에 샘플이 골고루 섞여 있지 않고 한쪽으로 치우쳐 있다면 샘플링 편향이라고 부릅니다.
✅문제 3. ② 행: 샘플, 열: 특성
입력 데이터는 행을 나타내는 샘플과 열을 나타내는 특성으로 구성됩니다.
올해 9월에 빅데이터분석기사 자격증 시험이 있는데 해당 자격증 필기 합격을 목표로 혼공학습단 활동을 열심히 해보려고 합니다. 이번 주는 머신러닝의 기초와 데이터를 다루는 방법에 대해서 알 수 있었습니다. 다음 주는 "Chapter 03. 회귀 알고리즘과 모델 규제"에 대해 공부할 예정이고, 다음 주에 또 만나요~ㅎㅎ
출처: 한빛미디어, 혼자 공부하는 머신러닝+딥러닝
'혼공학습단 > 혼자 공부하는 머신러닝+딥러닝' 카테고리의 다른 글
| [혼공학습단 10기] 6주차 미션 : Chapter 07 (0) | 2023.08.18 |
|---|---|
| [혼공학습단 10기] 5주차 미션 : Chapter 06 (0) | 2023.08.14 |
| [혼공학습단 10기] 4주차 미션 : Chapter 05 (0) | 2023.07.31 |
| [혼공학습단 10기] 3주차 미션 : Chapter 04 (0) | 2023.07.23 |
| [혼공학습단 10기] 2주차 미션 : Chapter 03 (0) | 2023.07.16 |



